keepalived nginx 高可用
!!! warning SElinux
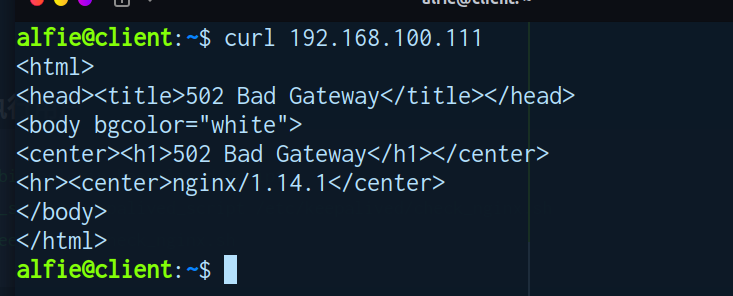
该配置需要关闭SELINXU,否则会出现 503 告警。
!!!
创建脚本执行用户
useradd -r -s /sbin/nologin keepalived_script
chown keepalived_script:keepalived_script /etc/keepalived/check_nginx.sh
chmod 655 /etc/keepalived/check_nginx.shNginx代理服务配置
/etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/doc/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
upstream demos {
server 192.168.100.103:80 weight=1; # 后端web服务器
server 192.168.100.104:80 weight=1; # 后端web服务器
}
server {
listen 80;
location /{
proxy_pass http://demos/;
}
}
}
~ 应用服务配置
yum -y install nginx
systemctl start nginx
echo "<h1>`hostname -I`</h1>" > /usr/share/nginx/html/index.htmlKeepalived 服务配置
! Configuration File for keepalived
global_defs {
router_id alfie_keepalive_1 # 备用节点修改名称
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.0.18
}
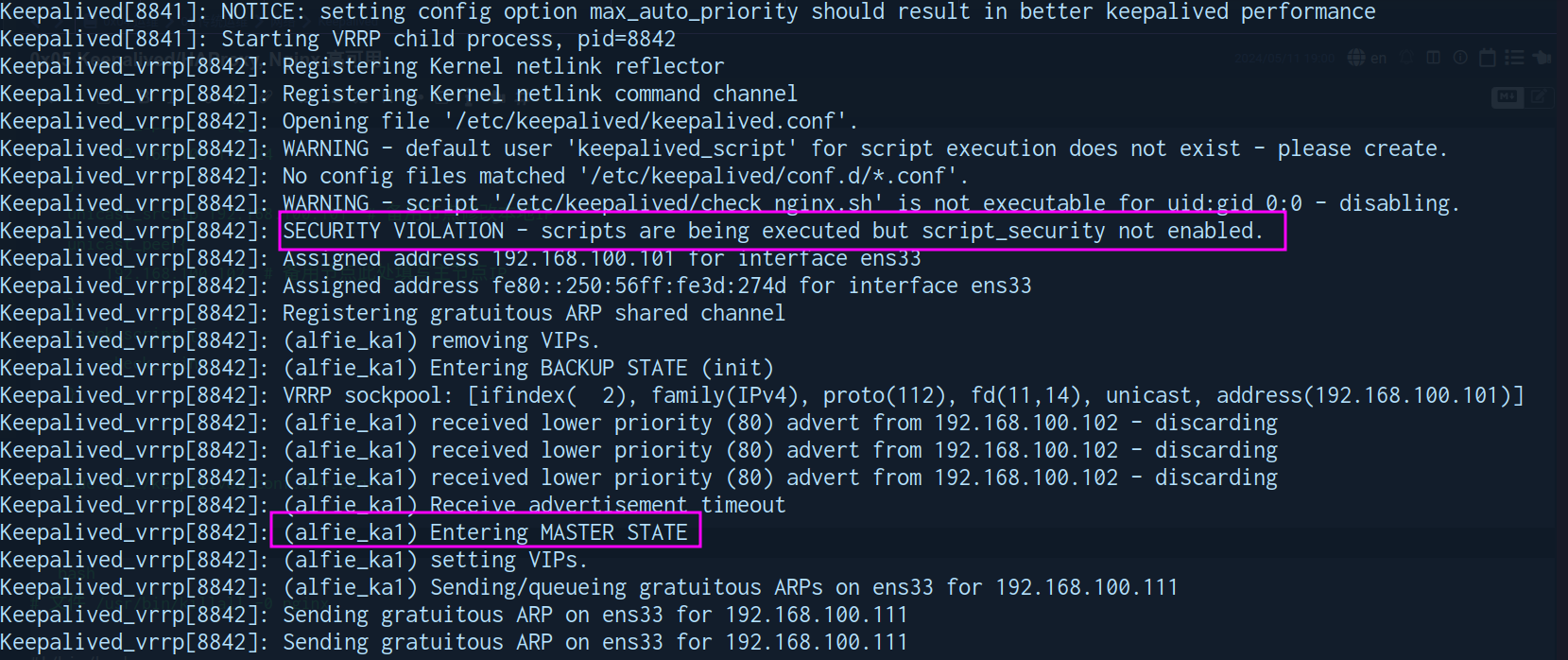
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh" # 使用 kill 发送 0 信号 确认程序是否工作正常
interval 1
weight -30 # 失败后降低 30 权重
fall 3
rise 5
timeout 2
}
vrrp_instance alfie_ka1 {
state MASTER # 备用节点为 BACKUP
interface ens33
virtual_router_id 61
priority 100 # 备用节点默认权重 80
advert_int 1
authentication {
auth_type PASS
auth_pass alopex
}
virtual_ipaddress {
192.168.100.111/24
}
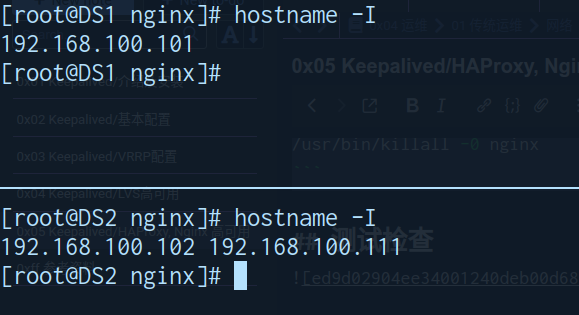
unicast_src_ip 192.168.100.101 # 备用节点修改本地IP
unicast_peer{
192.168.100.102 # 备用节点此处填写主节点IP
}
track_script {
check_nginx
}
}
include /etc/keepalived/conf.d/*.confchmod a+x /etc/keepalived/check_nginx.sh
# 文件 /usr/bin/killall -0 nginx
#!/bin/bash
/usr/bin/killall -0 nginx测试检查
-
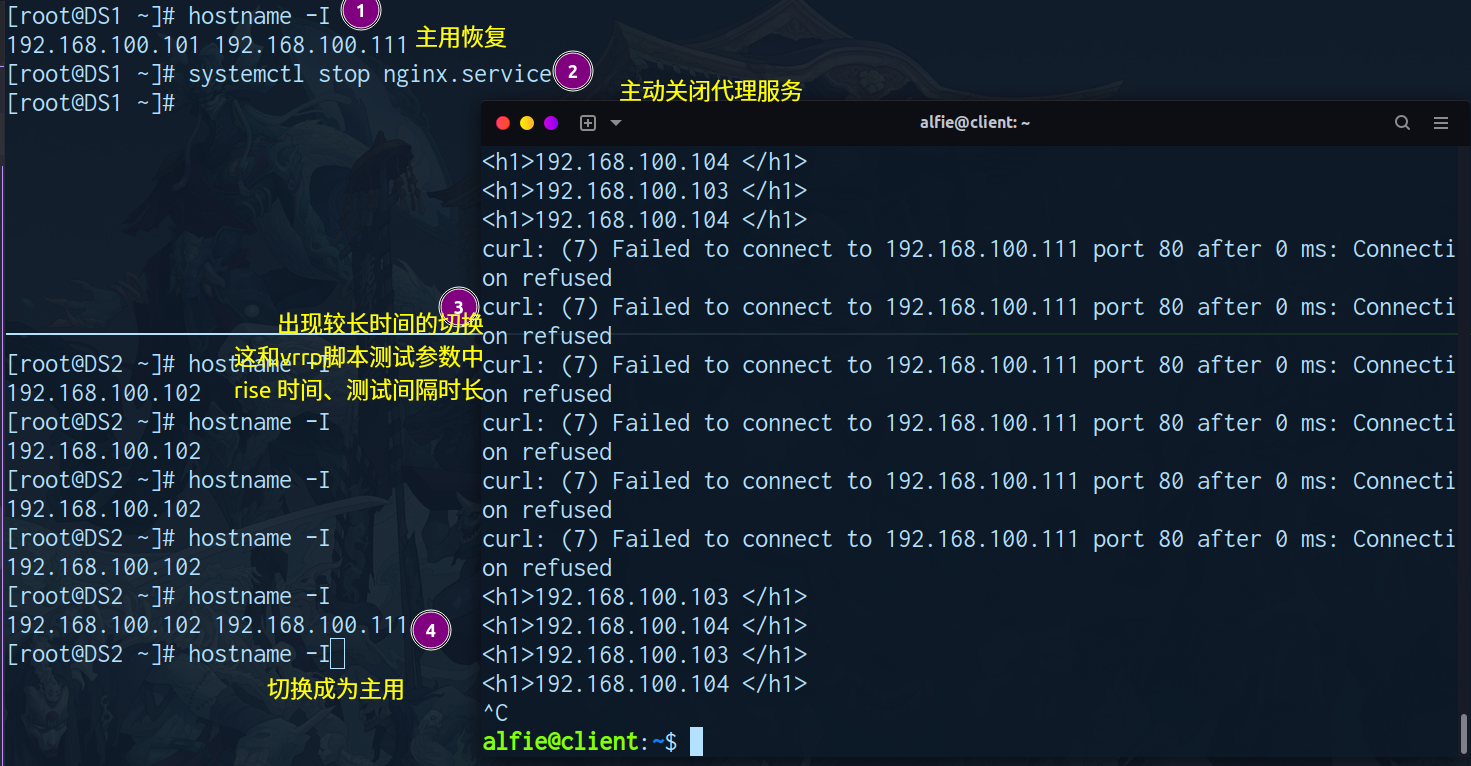
关闭DS1 keepalived
- 地址切换正常
- 应用访问正常
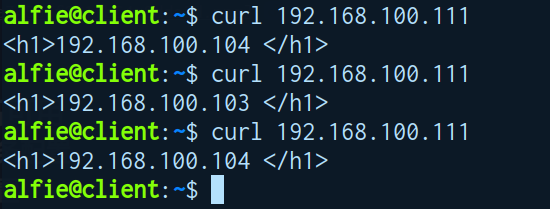
- 地址切换正常
-
关闭RS1
- 应用访问正常
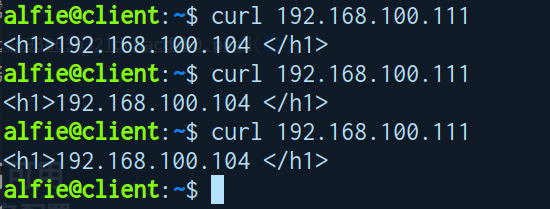
- 应用访问正常
-
健康检查 (恢复DS1 keepalived 关闭 nginx)
keepalived haproxy 高可用
HAProxy 服务配置
!!! warning 注意事项
# 绑定非自身IP地址
vim /etc/sysctl.conf
net.ipv4.ip_nonlocal_bind = 1
sysctl -p
# 在防火墙上放行通对VIP的访问
firewall-cmd --permanent --add-rich-rule='rule family="ipv4" destination address="192.168.100.111" accept'
firewall-cmd --reload!!!
global
daemon
stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin
nbthread 5
user haproxy
group haproxy
maxconn 100000
defaults
option http-keep-alive
maxconn 100000
mode http
timeout connect 300000ms
timeout client 300000ms
timeout server 300000ms
frontend demo-web-port
bind 192.168.100.111:80
mode http
use_backend demo-web
backend demo-web
mode http
default-server inter 1000 weight 6
server web2 192.168.100.103:80 weight 2 check addr 192.168.100.103 port 80
server web3 192.168.100.104:80 weight 2 check addr 192.168.100.104 port 80应用服务配置
yum -y install nginx
systemctl start nginx
echo "<h1>`hostname -I`</h1>" > /usr/share/nginx/html/index.htmlKeepalived 服务配置
! Configuration File for keepalived
global_defs {
router_id alfie_keepalive_1 # 备用节点修改名称
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.0.18
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 1
weight -30
fall 3
rise 5
timeout 2
}
vrrp_instance alfie_ka1 {
state MASTER # 备用节点修改为 BACKUP
interface ens33
virtual_router_id 61
priority 100 # 备用节点修改 80
advert_int 1
authentication {
auth_type PASS
auth_pass alopex
}
virtual_ipaddress {
192.168.100.111/24
}
unicast_src_ip 192.168.100.101 # 备用节点修改为本地IP
unicast_peer{
192.168.100.102 # 备用节点填主用节点IP
}
track_script {
check_haproxy
}
}
include /etc/keepalived/conf.d/*.conf
/etc/keepalived/check_haproxy.sh
chmod 655 /etc/keepalived/check_haproxy.sh
#!/bin/bash
if /usr/bin/killall -0 haproxy
then
exit 0
else
systemctl restart haproxy
fi检查测试
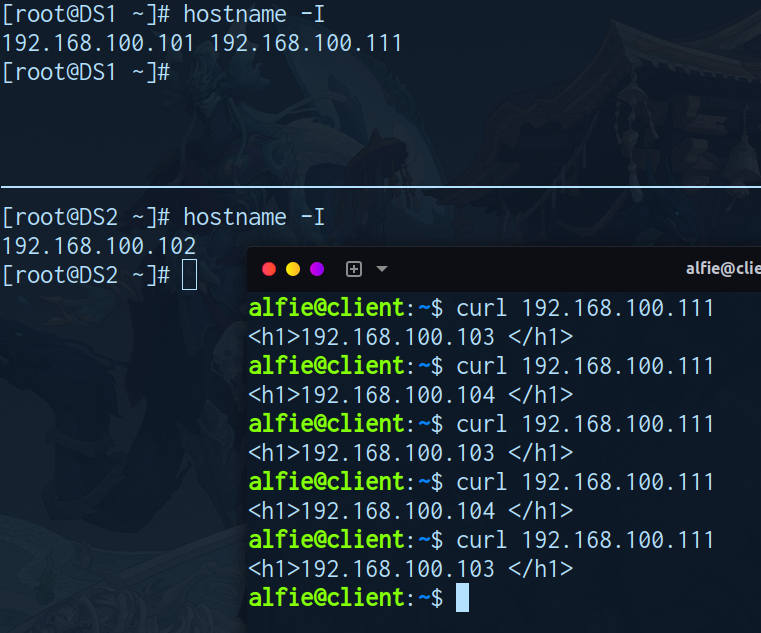

-
关闭DS1 (keepalived)
- 地址切换正常
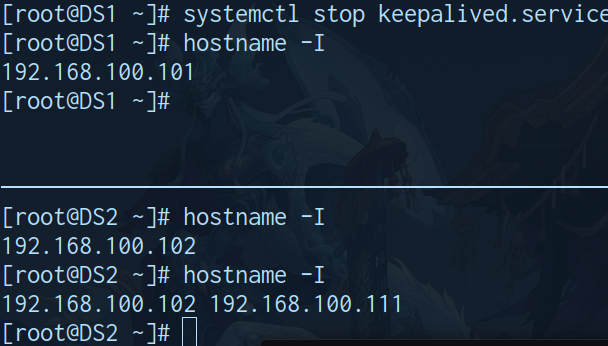
- 应用访问正常
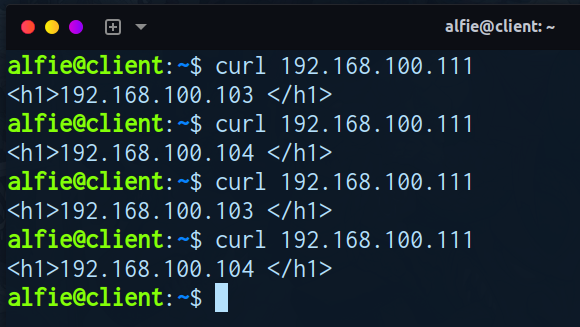
- 地址切换正常
-
关闭RS1
- 应用访问正常
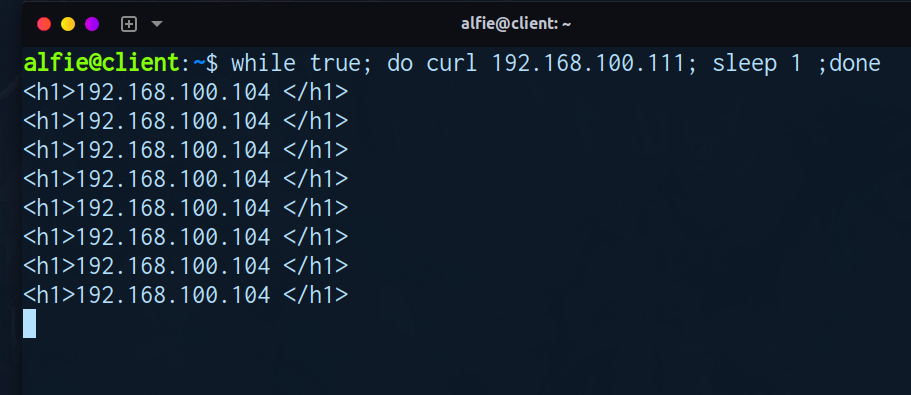
- 应用访问正常
-
健康检查(恢复keepalived 关闭DS1 (Haproxy))
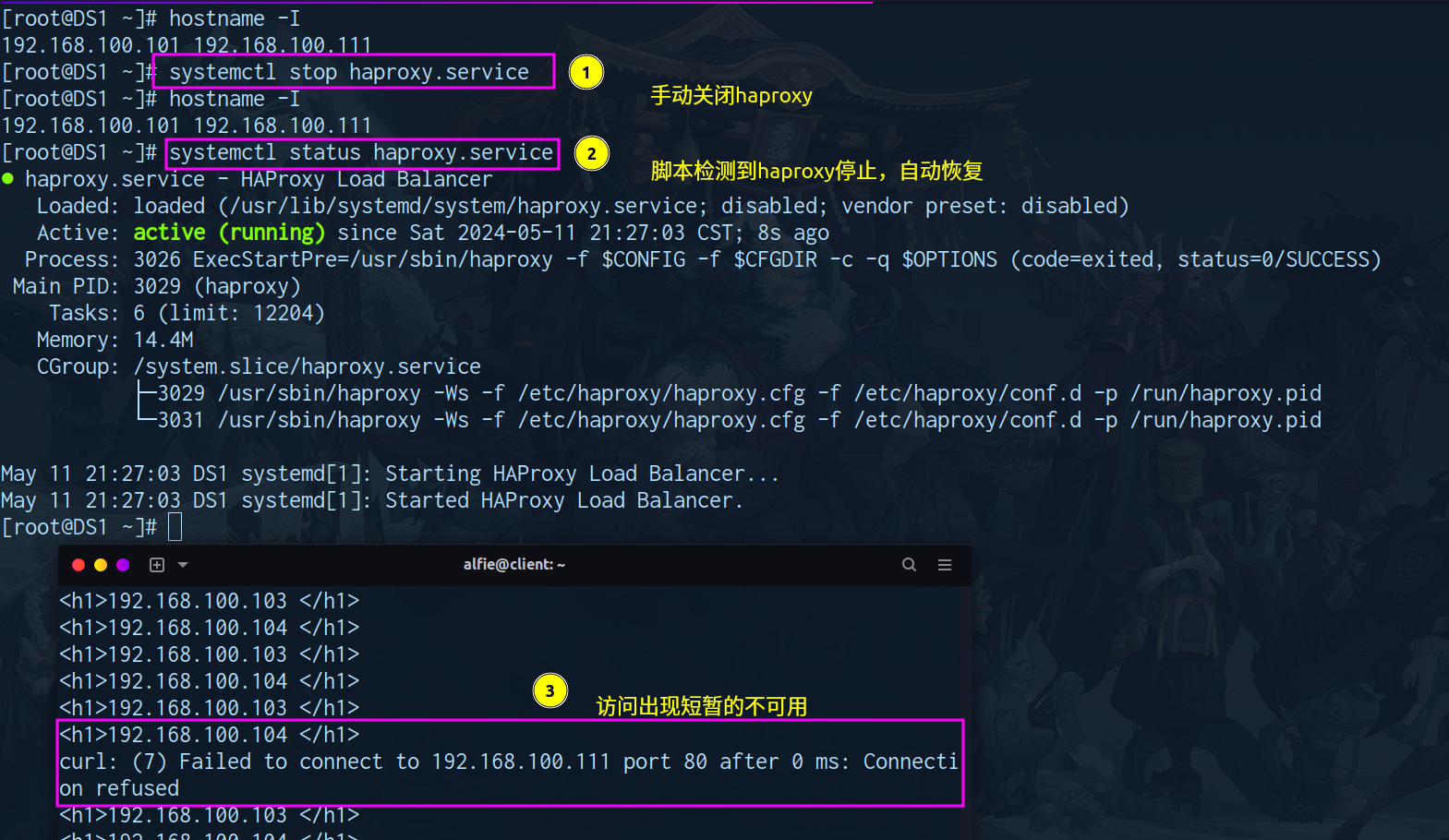
Redis 集群部署
部署
| 主机 | ip |
|---|---|
| s2 | 192.168.100.102 |
| s3 | 192.168.100.103 |
| s4 | 192.168.100.104 |
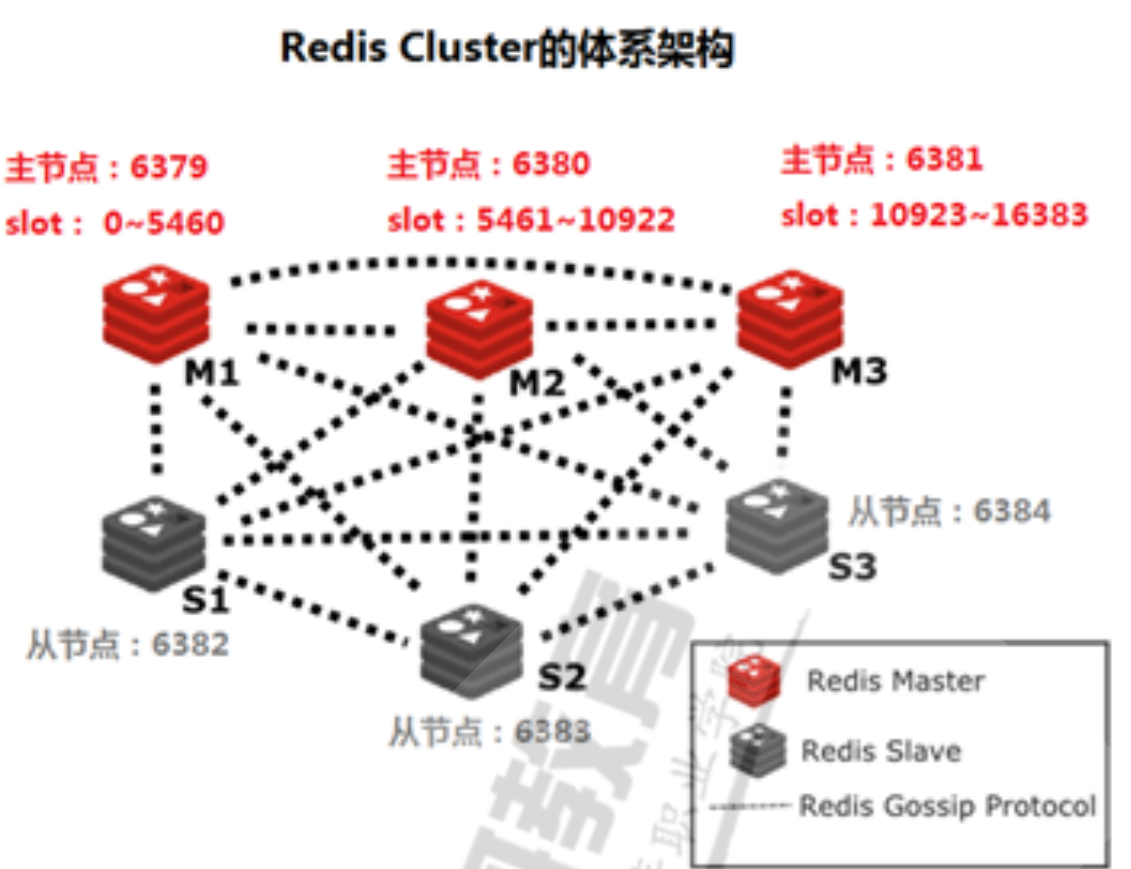
cluster (多主节点分区存放)
数据分布
解决把
整个数据集按照分区规则映射到多个节点的问题,每个节点负责整体数据的子集。
!!! info 分区方式
- 哈希分区
- 离散度好 / 数据分布与业务无关 / 无法顺序访问
- 代表产品:
redis cluster,Cassandra,Dynamo
- 顺序分区
- 离散度容易倾斜 / 数据分布业务相关 / 可以顺序访问
- 代表产品:
Bigtable,HBase,Hypertable

!!!
!!! abstract 哈希分区规则
-
节点取余分区
-
说明
节点取余分区方法通过简单的模运算将数据分布到不同的节点上。 -
算法简述
- 计算数据的哈希值
hash(key)。 - 用节点的数量
N对哈希值取模:partition = hash(key) % N。 - 将数据分配到
partition对应的节点。
- 计算数据的哈希值
-
优点
- 实现简单:算法非常直观,易于实现。
- 查询性能好:在节点数量固定的情况下,查询和插入操作的性能都很好。
-
缺点
- 扩展性差:当节点数量变化(增加或减少)时,大部分数据都需要重新分配,导致大量的数据迁移。
- 负载不均衡:如果哈希函数不好,可能导致数据分布不均匀,某些节点负载较高。
-
-
一致性哈希分区
-
说明
一致性哈希分区方法通过环形哈希空间和节点的虚拟副本来实现数据的分布和负载均衡。 -
算法简述
- 将所有节点映射到一个哈希环上。
- 计算数据的哈希值
hash(key)并将其放置在哈希环上。 - 从数据的位置顺时针找到第一个节点,这个节点就是数据的目标节点。
-
优点
- 扩展性好:当节点增加或减少时,只需要重新分配相邻节点的一部分数据,减少了数据迁移量。
- 负载均衡:通过添加虚拟节点,可以改善数据分布的均衡性。
-
缺点
- 实现复杂:相比节点取余分区,一致性哈希的实现要复杂得多。
- 性能略低:由于需要在哈希环上查找节点位置,可能会导致性能稍低。
-
-
虚拟槽分区
redis cluster实现-
说明
虚拟槽分区方法通过将哈希空间划分为固定数量的槽,并将这些槽映射到实际节点上。 -
算法简述
- 将哈希空间分成固定数量的槽(如
M个)。 - 计算数据的哈希值
hash(key)并将其映射到某个槽:slot = hash(key) % M。 - 将槽映射到实际的节点:
partition = slot_to_node(slot)。
- 将哈希空间分成固定数量的槽(如
-
优点
- 扩展性好:增加或减少节点时,只需重新分配一部分槽到新的节点,数据迁移量适中。
- 负载均衡:通过合理地分配槽,可以实现较为均衡的负载分布。
-
缺点
- 实现复杂:需要实现槽到节点的映射管理,增加了系统的复杂度。
- 管理开销:需要维护槽和节点之间的映射关系,增加了系统的管理开销。
!!!
-
!!! danger redis虚拟槽位信息
设置有0 ~ 16383的槽,共 16384 个数据单元,每个槽映射一个数据子集。
通过hash函数,将数据存放在不同的槽位中,每个集群的节点保存一部分的槽。
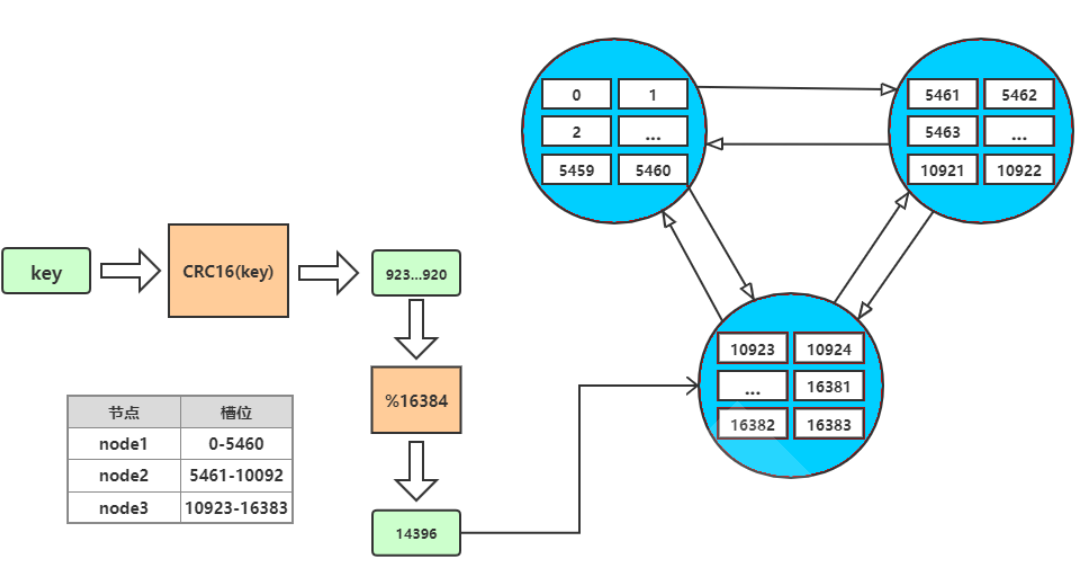
集群之间的通信可以保证,最多两次就能命中对应槽所在的节点。
!!!
搭建部署
需要先部署redis集群
0xff redis/脚本使用#个人源安装脚本
| 主机 | ip |
|---|---|
| s2 | 192.168.100.102 |
| s3 | 192.168.100.103 |
| s4 | 192.168.100.104 |
修改参数
# 修改配置文件
# 以下与cluster相关,按需开启
# -e '/# cluster-enabled yes/a cluster-enabled yes' \
# -e '/# cluster-config-file nodes-6379.conf/a cluster-config-file nodes-6379.conf' \
# -e '/cluster-require-full-coverage yes/a cluster-require-full-coverage no' \
sed -i.bak \
-e 's/appendonly no/appendonly yes/' \
-e '/masterauth/a masterauth alopex' \
-e 's/bind 127.0.0.1/bind 0.0.0.0/' \
-e "/# requirepass/a requirepass alopex" \
-e "/^dir .*/c dir /apps/redis/data/" \
-e "/logfile .*/c logfile /apps/redis/log/redis-6379.log" \
-e "/^pidfile .*/c pidfile /apps/redis/run/redis_6379.pid" \
-e '/# cluster-enabled yes/a cluster-enabled yes' \
-e '/# cluster-config-file nodes-6379.conf/a cluster-config-file /apps/redis/etc/nodes-6379.conf' \
-e '/cluster-require-full-coverage yes/a cluster-require-full-coverage no' \
/apps/redis/etc/redis.conf
# 启动服务
systemctl daemon-reload
systemctl enable --now redis创建集群
集群功能已开启
cluster 状态启动

16379 端口已启动

创建集群
# 三个节点不创建 slave 节点
redis-cli -a alopex --cluster create 192.168.100.102:6379 192.168.100.103:6379 192.168.100.104:6379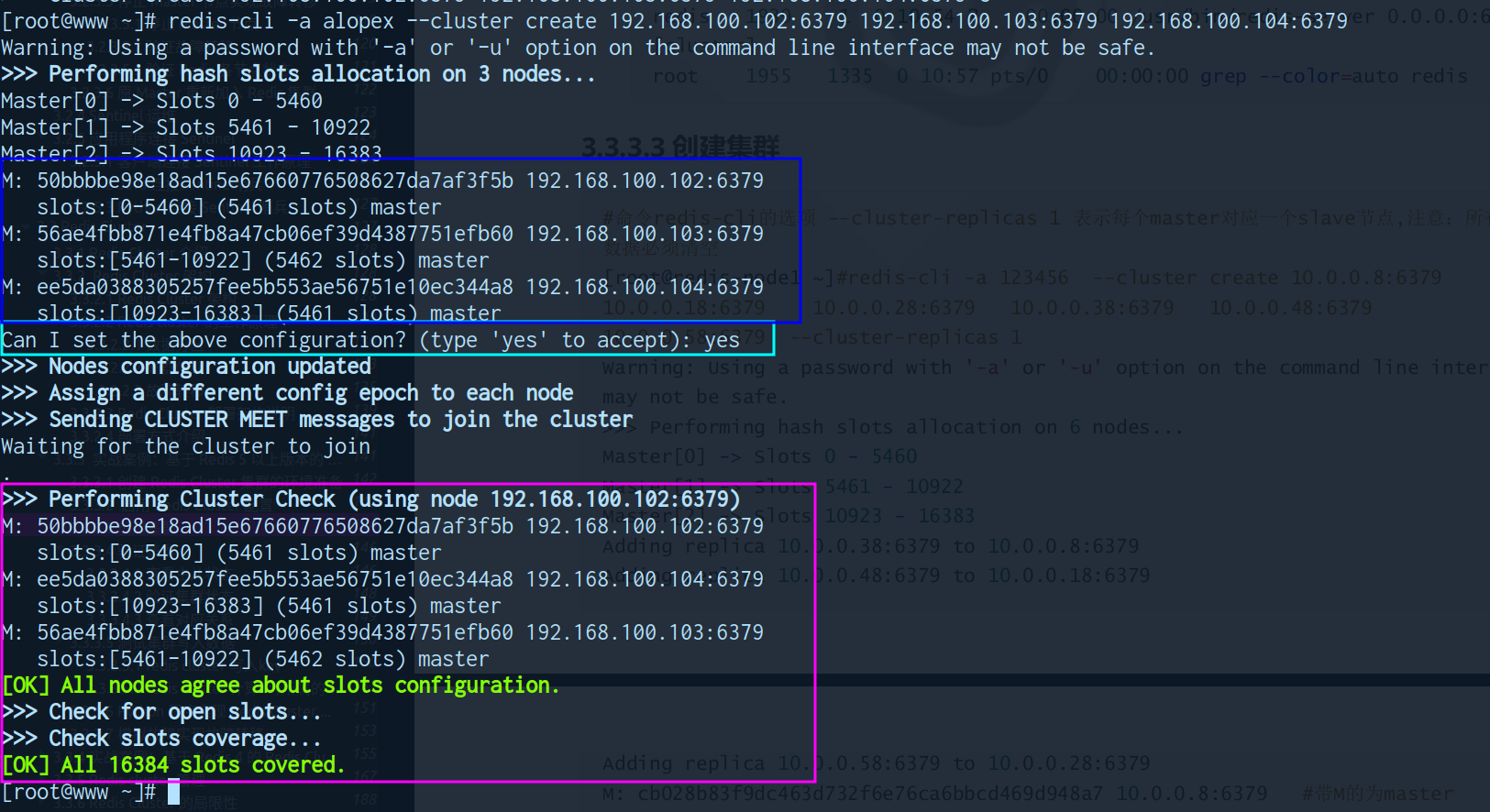
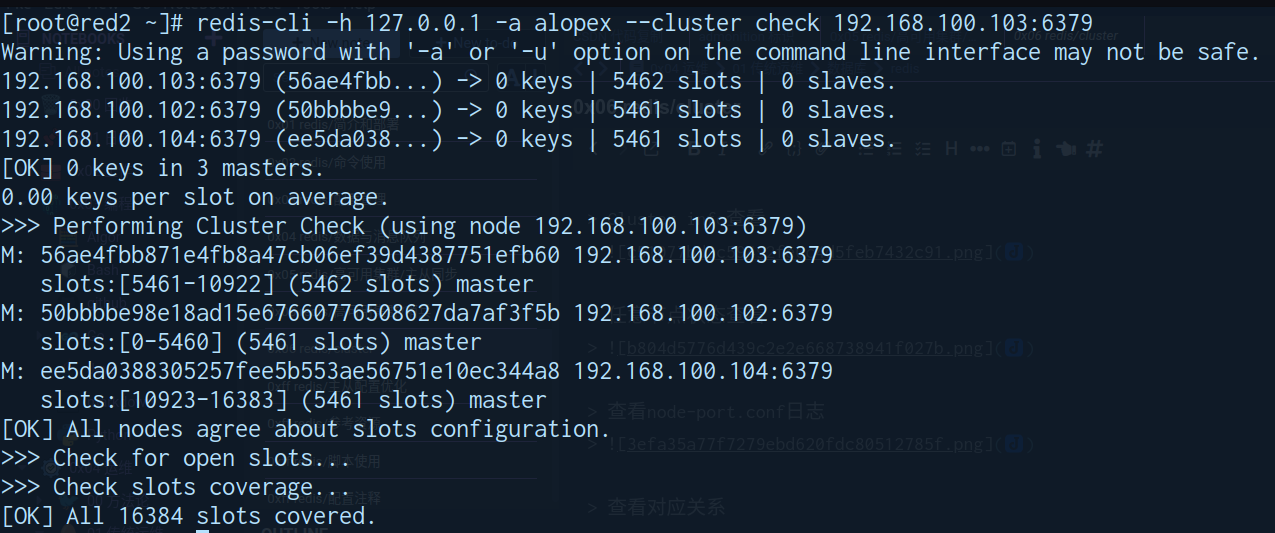
验证集群
master1 节点查看
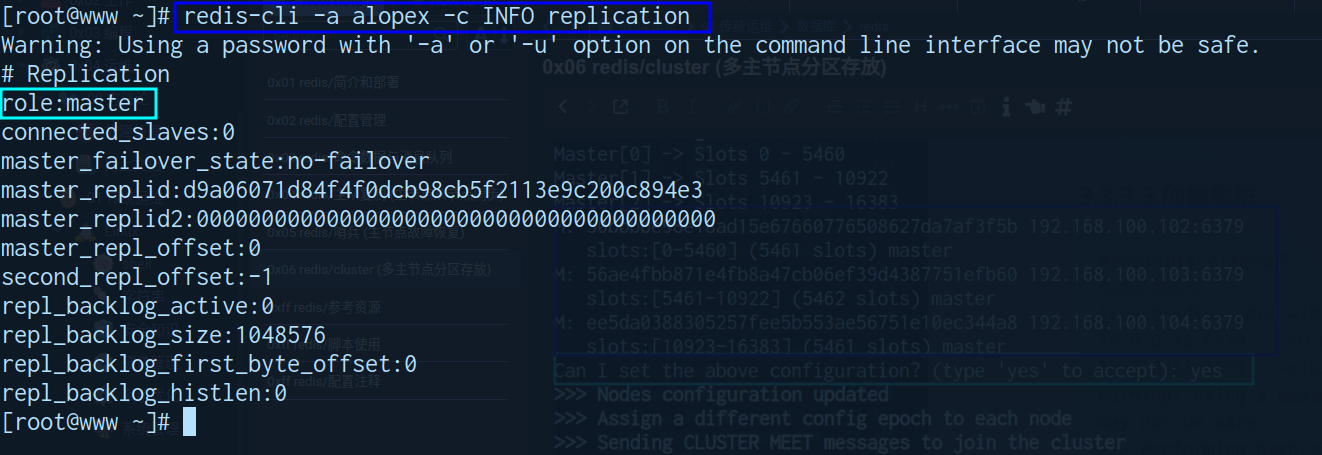
node节点状态查看

Cluster info查看
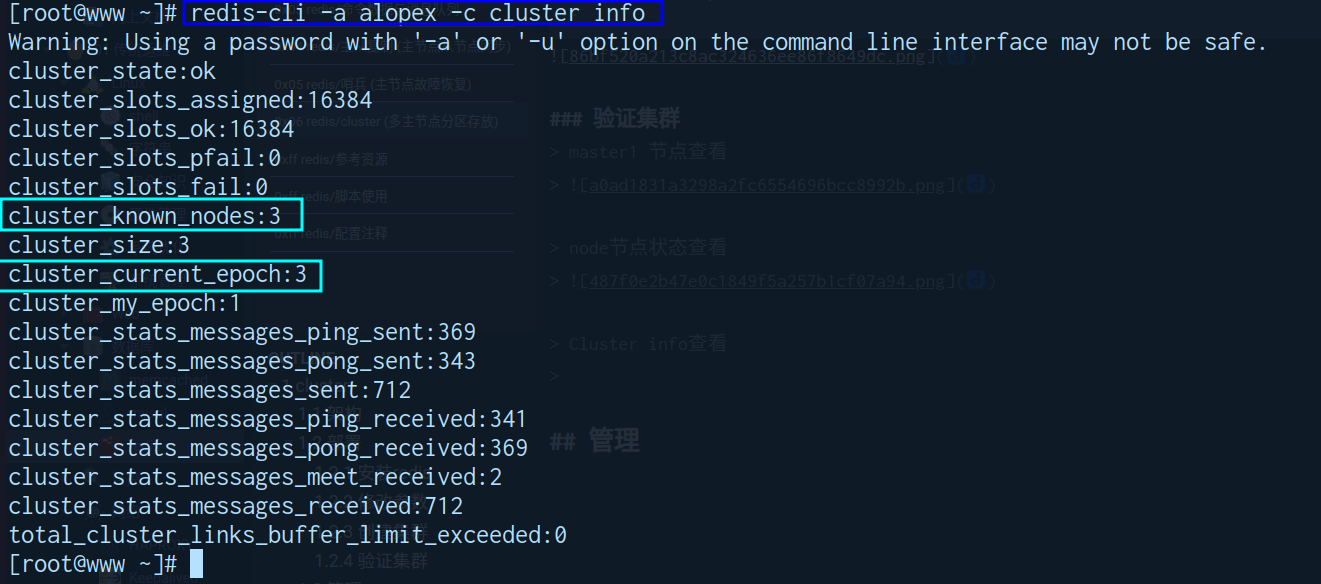
任意节点状态查看

查看node-port.conf日志

查看对应关系
集群命令
// 集群(cluster)
CLUSTER INFO 打印集群的状态信息
CLUSTER NODES 列出集群当前已知的所有节点(node),以及这些节点的相关信息
// 节点(node)
CLUSTER MEET <ip> <port> 将ip和port所指定的节点添加到集群当中,让它成为集群的一份子
CLUSTER FORGET <node_id> 从集群中移除node_id指定的节点
CLUSTER REPLICATE <node_id> 将当前节点设置为node_id指定节点的从节点
CLUSTER SAVECONFIG 将当前节点的配置信息手动保存到硬盘(nodes-port.conf)
CLUSTER SLAVES <master_node_id> 查询指定的master_node_id主节点有哪些从(slave)节点
// 槽(slot)
CLUSTER ADDSLOTS <slot> [slot ...] 将一个或多个槽(slot)指派(assign)给当前节点
CLUSTER DELSLOTS <slot> [slot ...] 将一个或多个槽从当前节点移除
CLUSTER FLUSHSLOTS 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点
CLUSTER SETSLOT <slot> NODE <node_id> 将当前节点指定的槽(slot)指派给node_id指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽,然后再进行指派
CLUSTER SETSLOT <slot> MIGRATING <node_id> 将当前节点指定的槽(slot)迁移到node_id指定的节点中
CLUSTER SETSLOT <slot> IMPORTING <node_id> 从node_id指定节点中的槽(slot)导入到当前节点
CLUSTER SETSLOT <slot> STABLE 取消对当前节点指定槽(slot)的导入(import)或者迁移(migrate)
CLUSTER SLOTS 查看槽(slot)在集群中的分配情况
// 键 (key)
CLUSTER KEYSLOT <key> 计算键key应该被分配在哪个槽上
CLUSTER COUNTKEYSINSLOT <slot> 返回指定槽(slot)保存key的数量
CLUSTER GETKEYSINSLOT <slot> <count> 获取指定槽(slot)中count个key,如果指定槽中大于count个key,则只返回前cout个key,小于或为空,则返回最多数量的key 读写操作
写入数据
-
流程图
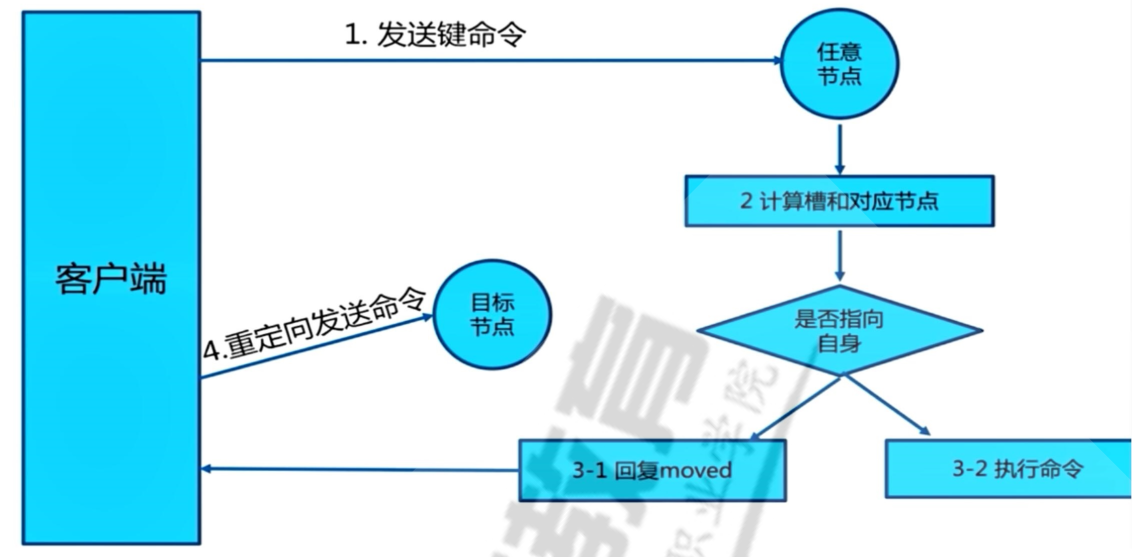
-
写入实例
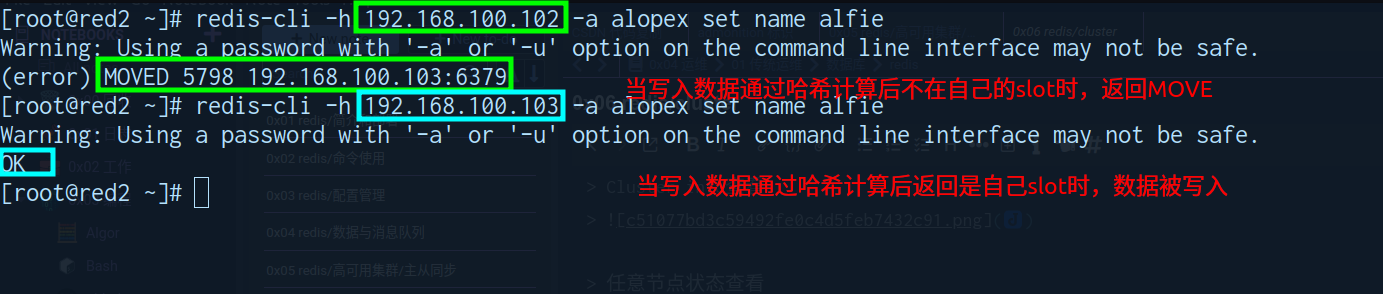
计算slot
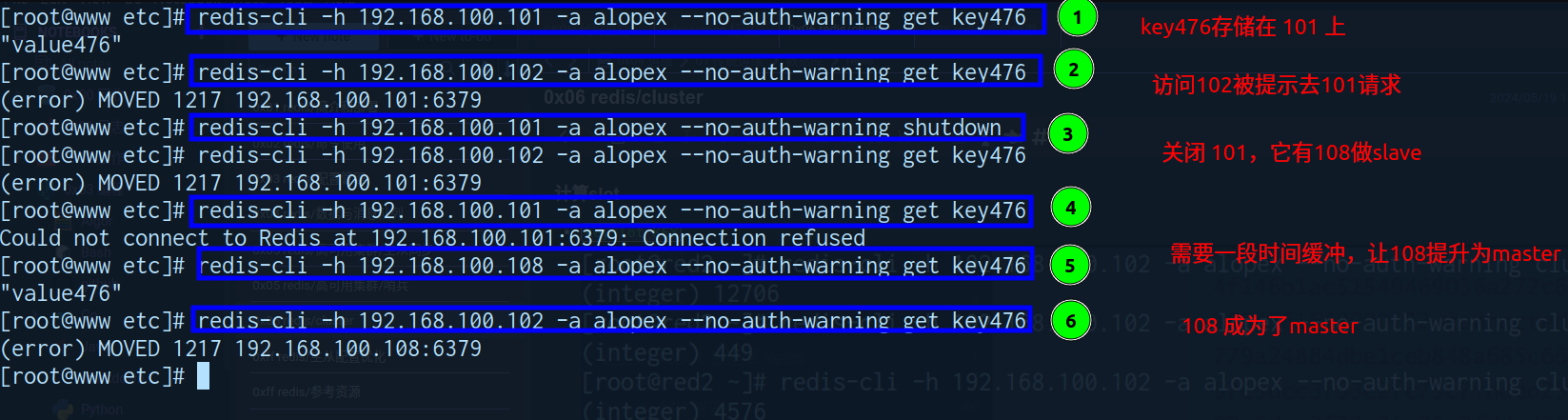
keyslot KEY
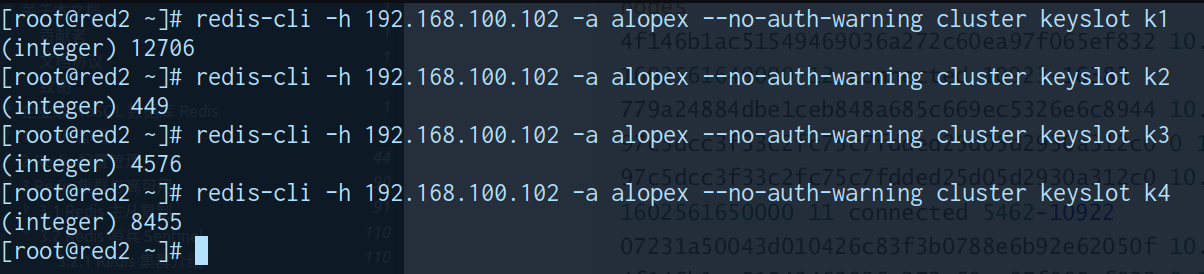
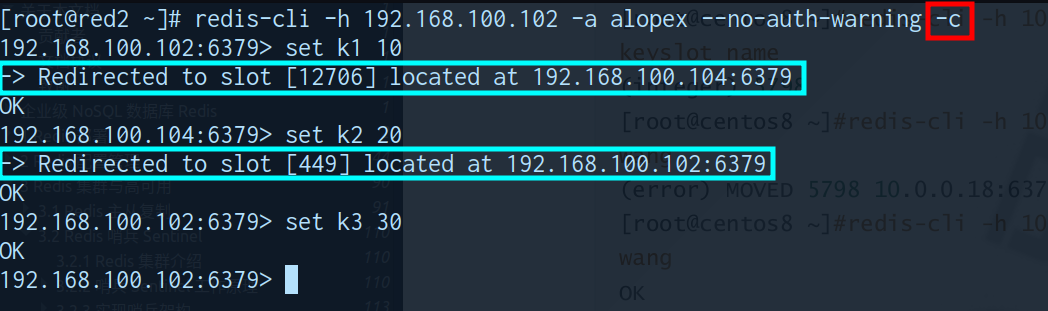
集群方式链接
-c自动实现slot重定向
python客户端访问
需要先使用 pip 安装
redis-py-cluster
0xff redis/脚本使用#cluster调用
测试结果可见分布较为平均
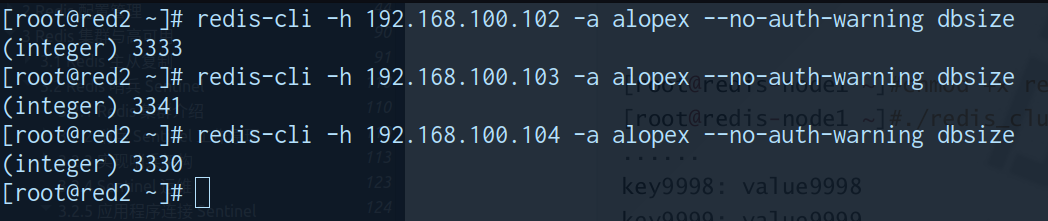
管理
增加slave节点
- 0xff redis/脚本使用#源安装脚本
- 修改参数
- 查询master节点的 master-id
redis-cli -h 127.0.0.1 -a alopex --no-auth-warning cluster nodes

- 添加 slave 节点
redis-cli -a <auth-passwd> \ --cluster add-node <current-slave-node:6379> <oneof-cluster-node:6379> \ --cluster-slave --cluster-master-id <cluster-master-id>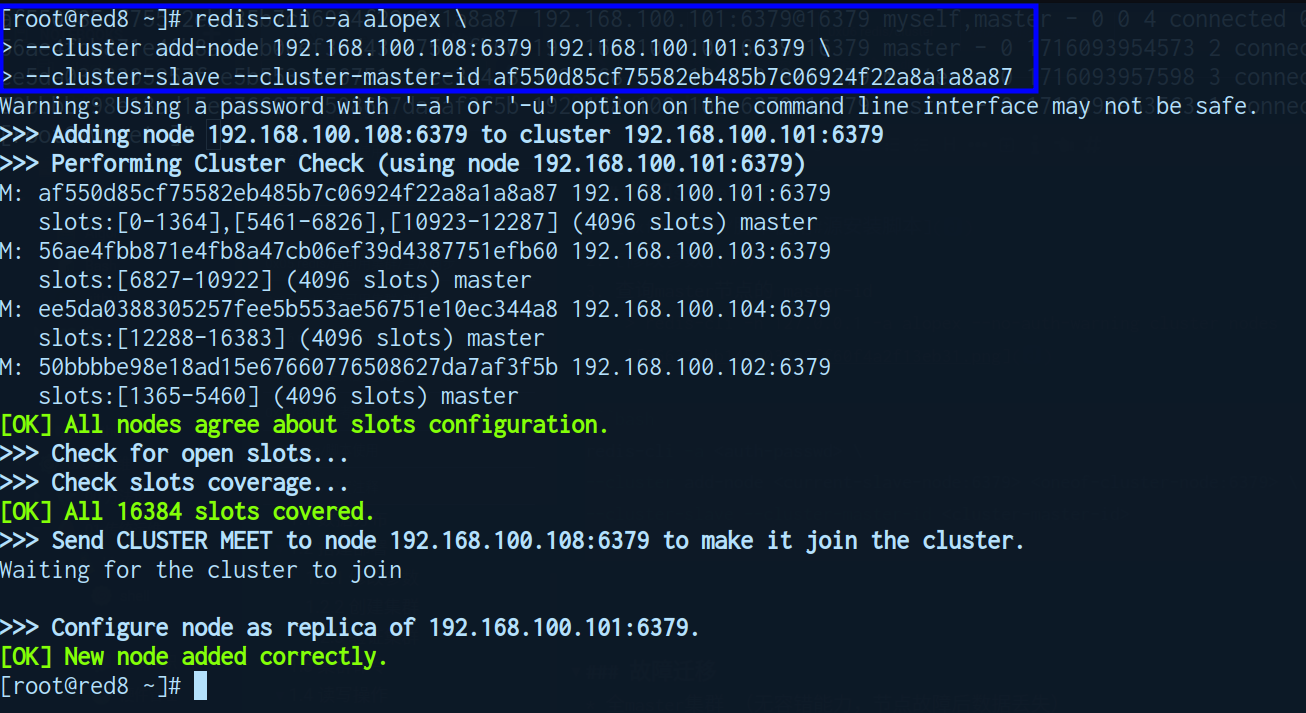
- 确认新增 slave

故障迁移
-
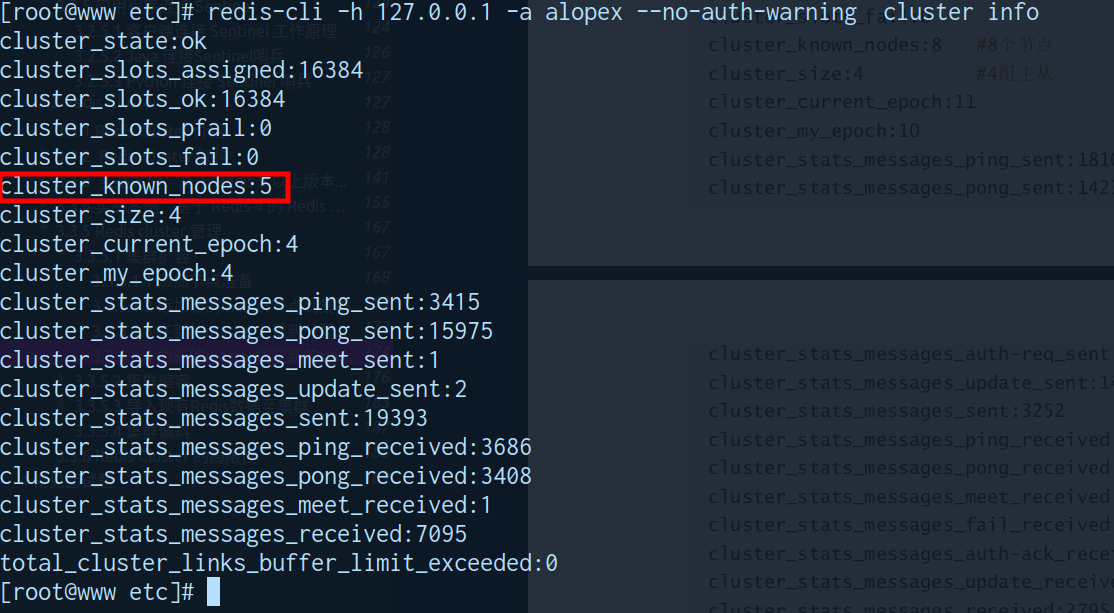
全master集群 (无容错能力,节点故障后数据丢失)
- 需要实现故障迁移,应在设计至少使用
6台主机或为其增加slave节点redis-cli -a 123456 --cluster-replicas \ --cluster-replicas \ --cluster create 10.0.0.18:6379 10.0.0.28:6379 10.0.0.58:6379 \ 10.0.0.8:6379 10.0.0.38:6379 10.0.0.48:6379
- 需要实现故障迁移,应在设计至少使用
-
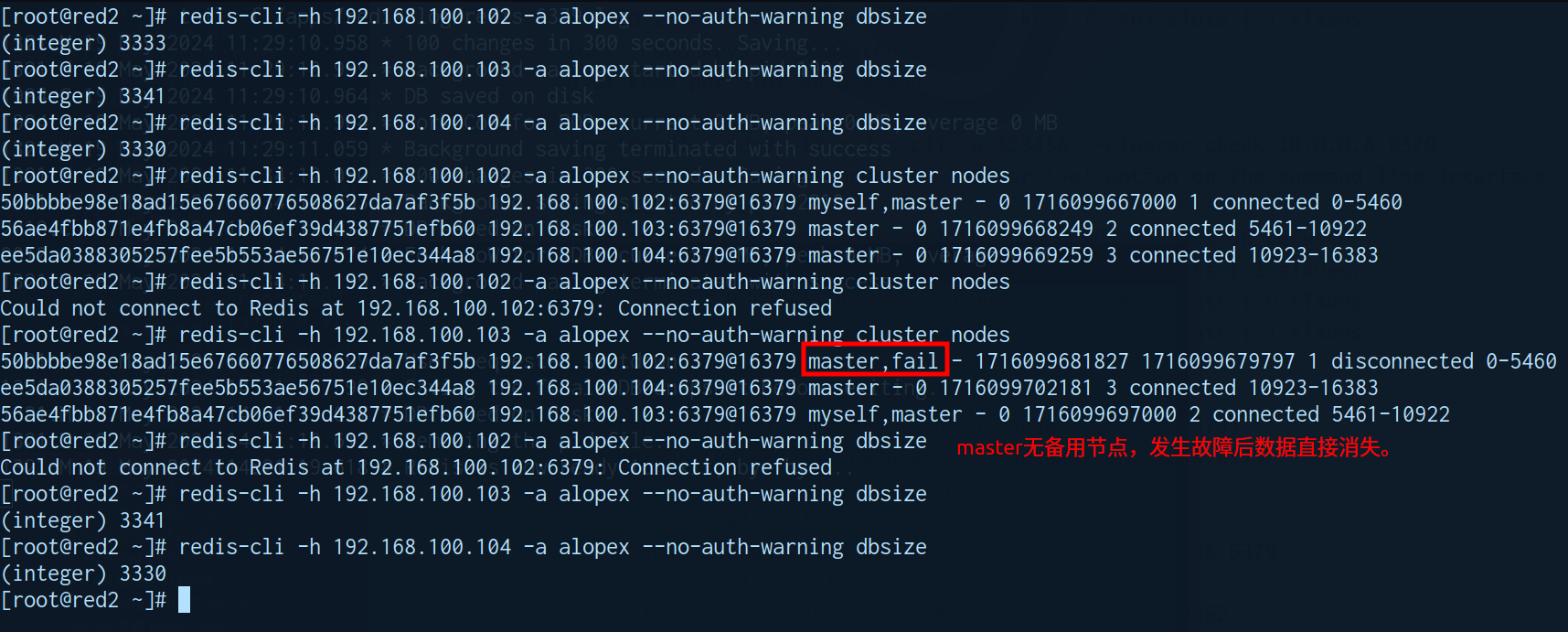
拥有slave节点的master节点故障 (拥有容错能力,主节点故障后slave节点会顶替工作)

集群扩容
!!! success 场景思路
场景:现有的Redis cluster架构已经无法满足越来越高的并发访问请求,需要添加新的主机提高并发能力。
思路:先添加节点,在扩展槽位,最后为master加上slave。
!!!
!!! warning master数量
注意: 生产环境一般建议master节点为奇数个,比如:3,5,7,以防止脑裂现象
< 本地为实验环境,为方便操作仅添加一台master,凑成4台master。>
!!!
- 步骤图解
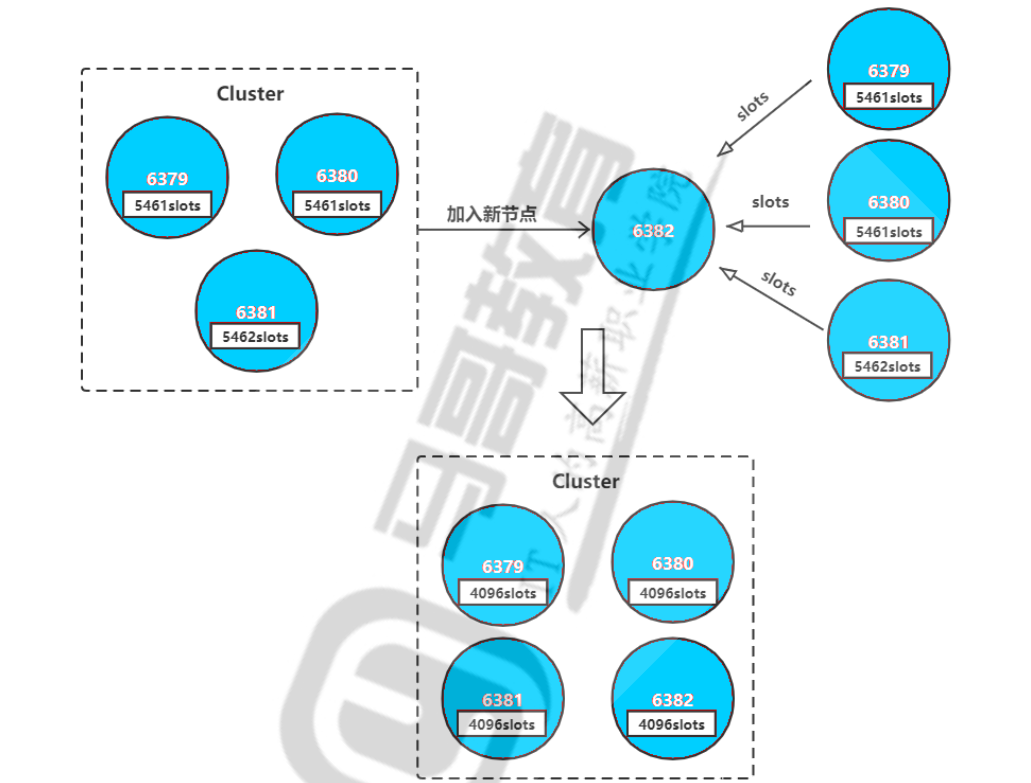
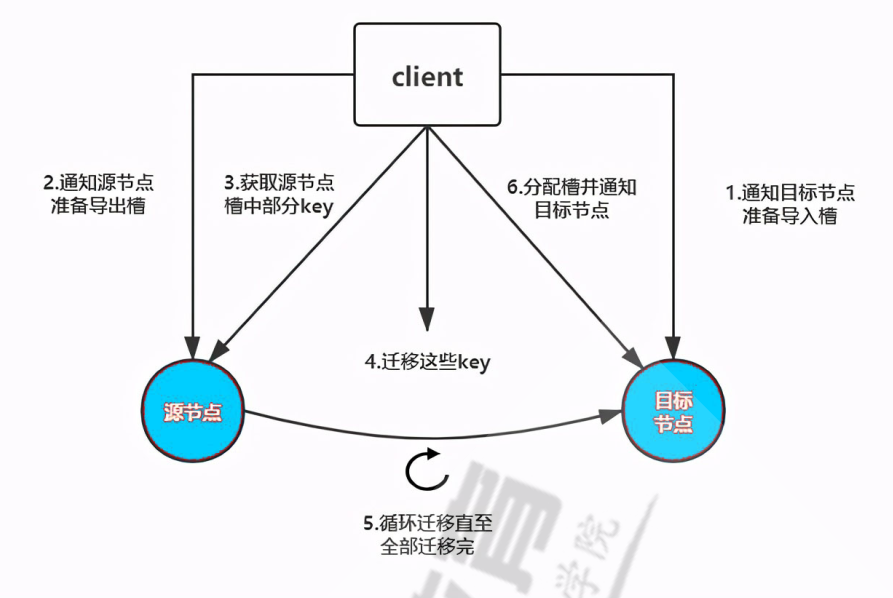
!!! info 实际操作
0. 查看当前 slot 分配信息

2. 准备新的redis节点,配置使用cluster配置
0xff redis/脚本使用#个人源安装脚本
修改参数
2. 添加新的master节点到集群
redis-cli -a <auth-passwd> --cluster add-node <current-node-ip:6379> <oneof-cluster-node-ip:6379>
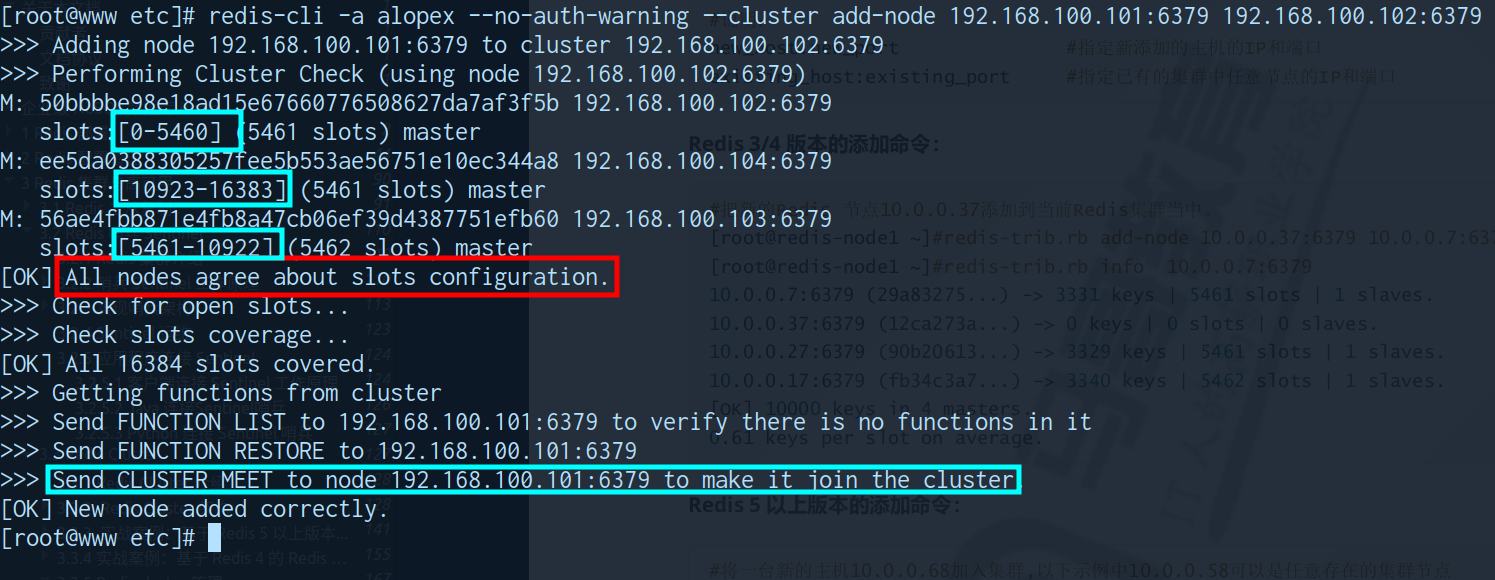
3. 检查是新节点是否连接
> redis-cli -h 192.168.100.102 -a alopex --no-auth-warning --cluster info 192.168.100.101:6379

4. 重新分配 slot (仅5+版本支持在线扩容,旧版本需要备份、清空槽数据、再恢复)
redis-cli -a <auth-passwd> --cluster reshard <oneof-cluster-node-ip>:6379
* slot数量
* 需要分配的 slot 数量 (16384/master个数)
* 接收slot的ID
* 新的master的ID (没有slot的主机,新加入的主机)
* 接收slot的策略 (新增选择 ALL)
* 使用 "all":当你想要将集群中所有现有节点都指定为哈希槽的源节点时,你会使用 "all"。
* 这在你向集群添加新节点时很有用,你希望现有节点将它们的哈希槽均匀地分配给它们自己和新节点。
* 使用 "done":当你完成手动输入所有源节点ID的任务时,你会使用 "done"。
* 这表示你已经完成了指定哈希槽重新分配的源节点的任务。
5. 检查新的 slot 分配信息

6. 如集群中需要从节点,可选择对slave扩容
增加slave节点
!!!
集群缩容
!!! success 场景思路
场景:随着业务萎缩用户量下降明显,redis服务器负载出现闲置,需要对其进行资源释放
思路:再回收槽位,删除主节点,最后删除从节点。
!!!
!!! info 实际操作
0. 当前集群情况 (master:4, slave:1)

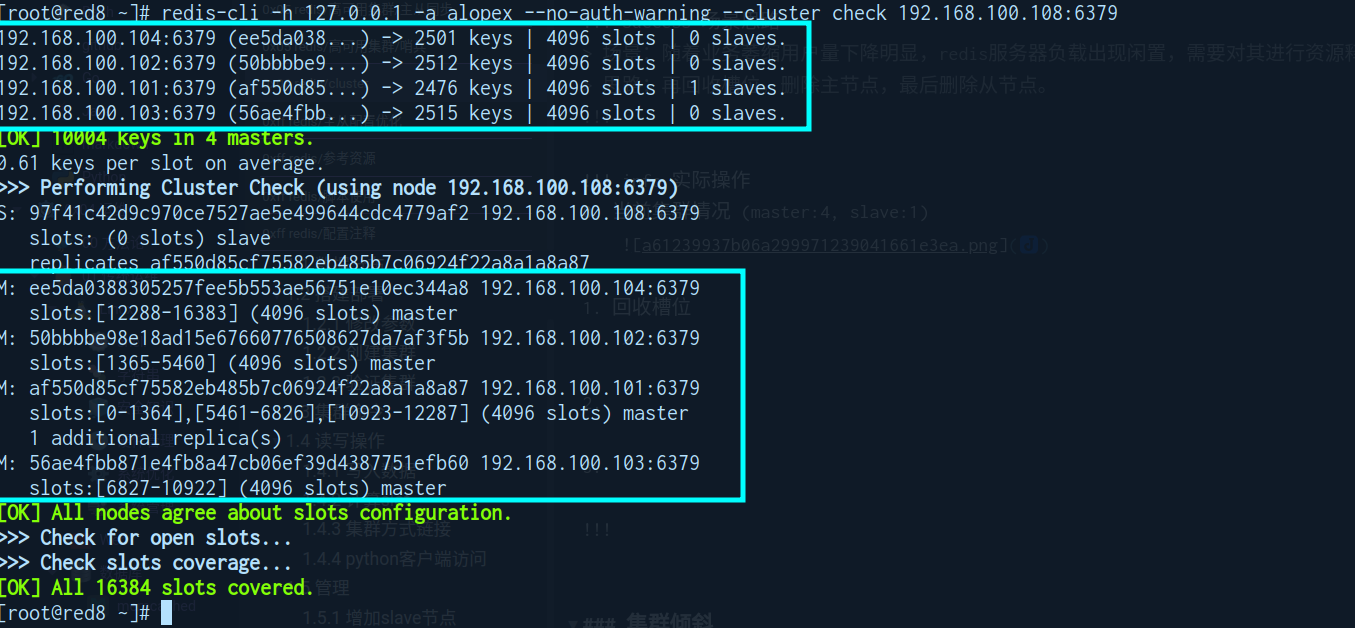
-
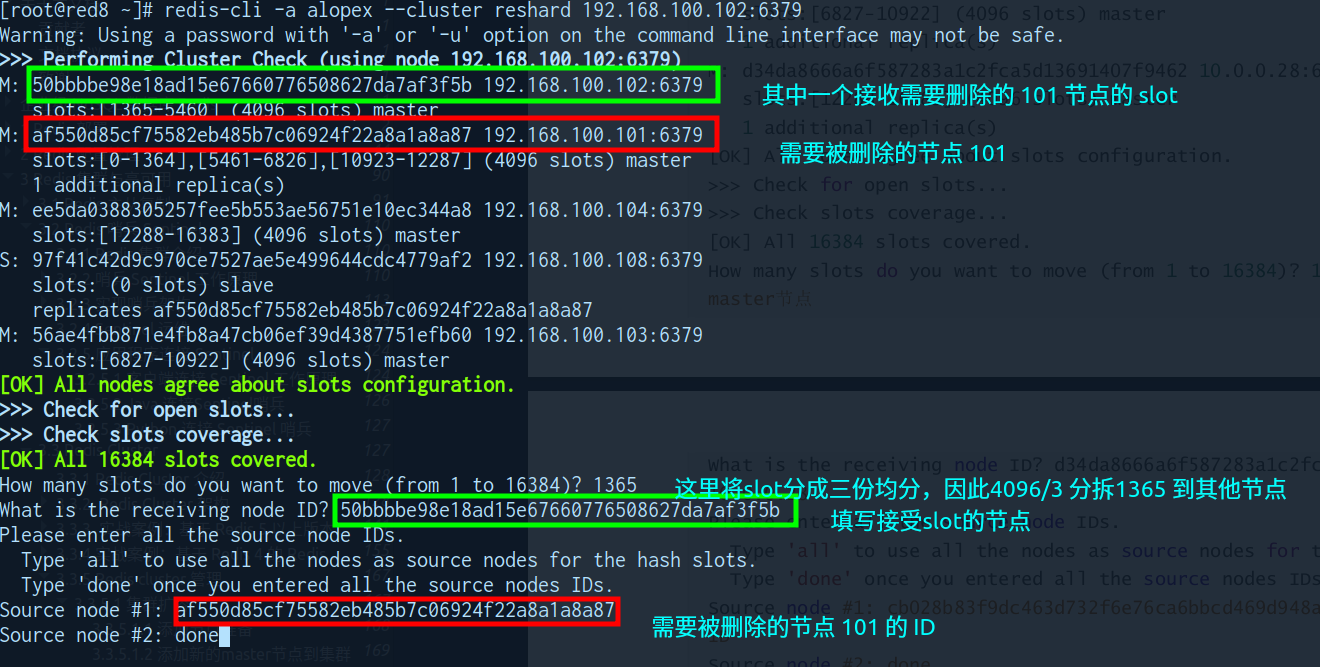
回收槽位
redis-cli -a <auth-passwd> --cluster reshard <oneof-cluster-node-ip>:6379- slot数量
- 需要分配的
slot数量 (回收主机拥有slot数/回收后master数量 --> 4096/3=1365) - 此处使用了均分的方式,因此每次
只移动1/3的slot
- 需要分配的
- 接受slot的ID (选择用于回收slot的master ID,多master可以任选)
- 用于接收释放的
slot
- 用于接收释放的
- 回收slot的策略 (删除写入
需要删除的节点-->Done)- 使用 "all":当你想要将集群中所有现有节点都指定为哈希槽的源节点时,你会使用 "all"。
- 这在你
向集群添加新节点时很有用,你希望现有节点将它们的哈希槽均匀地分配给它们自己和新节点。
- 这在你
- 使用 "done":当你
完成手动输入所有源节点ID的任务时,你会使用 "done"。- 这表示你已经完成了指定哈希槽重新分配的源节点的任务。
- 使用 "all":当你想要将集群中所有现有节点都指定为哈希槽的源节点时,你会使用 "all"。
- 交互式执行 (1次)
- 非交互形式执行 (2次)
redis-cli -a <auth-passwd> --cluster reshard 192.168.100.102:6379 \ --cluster-slots 1365 --cluster-from <node-need-to-delete-ID> \ --cluster-to <node-will-receive-slot-ID> --cluster-yes eg: # 103 接收 101 放弃的 1365 个 slot redis-cli -a alopex --cluster reshard 192.168.100.102:6379 \ --cluster-slots 1365 --cluster-from af550d85cf75582eb485b7c06924f22a8a1a8a87 \ --cluster-to 56ae4fbb871e4fb8a47cb06ef39d4387751efb60 --cluster-yes # 104 接收 101 放弃的 1366 个 slot redis-cli -a alopex --cluster reshard 192.168.100.102:6379 \ --cluster-slots 1366 --cluster-from af550d85cf75582eb485b7c06924f22a8a1a8a87 \ --cluster-to ee5da0388305257fee5b553ae56751e10ec344a8 --cluster-yes
- slot数量
-
确认slot已被回收
redis-cli -h 127.0.0.1 -a alopex --no-auth-warning --cluster check 192.168.100.108:6379
可以看到此前的 101 和 108 默认成为了 104 的 slave
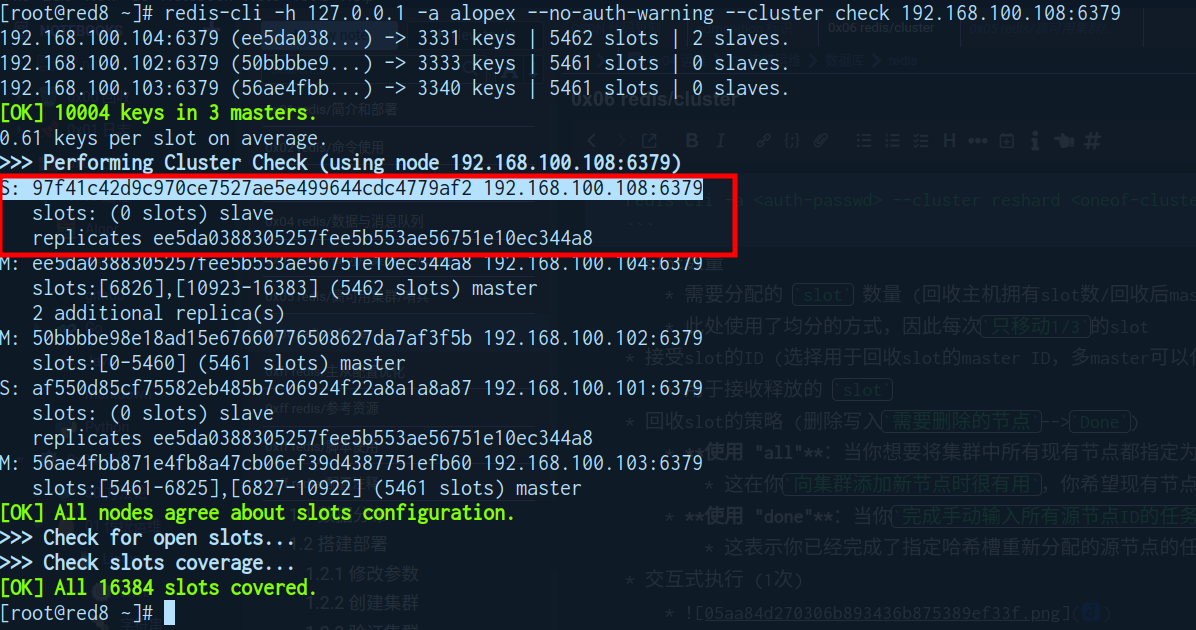

-
删除slave节点
redis-cli -a <\auth-passwd> --cluster del-node <\oneof-cluster-node>:6379 <\slave-node-need-to-del-ID>

-
节点信息更新
redis-cli -a <\auth-passwd> --no-auth-warning cluster nodes

!!!
集群倾斜
场景:多个节点运行一段时间后,可能会出现倾斜现象,某个节点数据偏多,内存消耗更大,
-
原因:
- 节点和槽分配不均
- 不同槽对应键值数量差异较大
- 包含bigkey,建议少用
- 内存相关配置不一致
- 热点数据不均衡 : 一致性不高时,可以使用本缓存和MQ
-
解决方式
- 执行自动的槽位重新平衡分布,但
会影响客户端的访问 - redis-cli --cluster rebalance <集群节点IP:PORT>
- 执行自动的槽位重新平衡分布,但